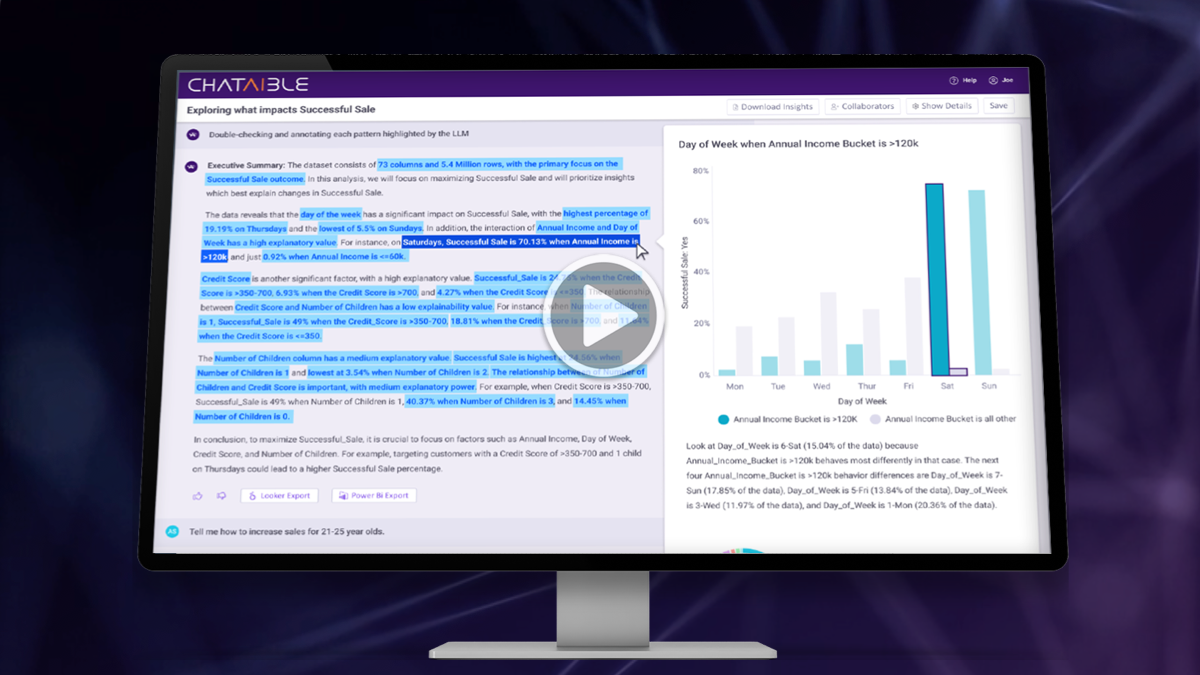





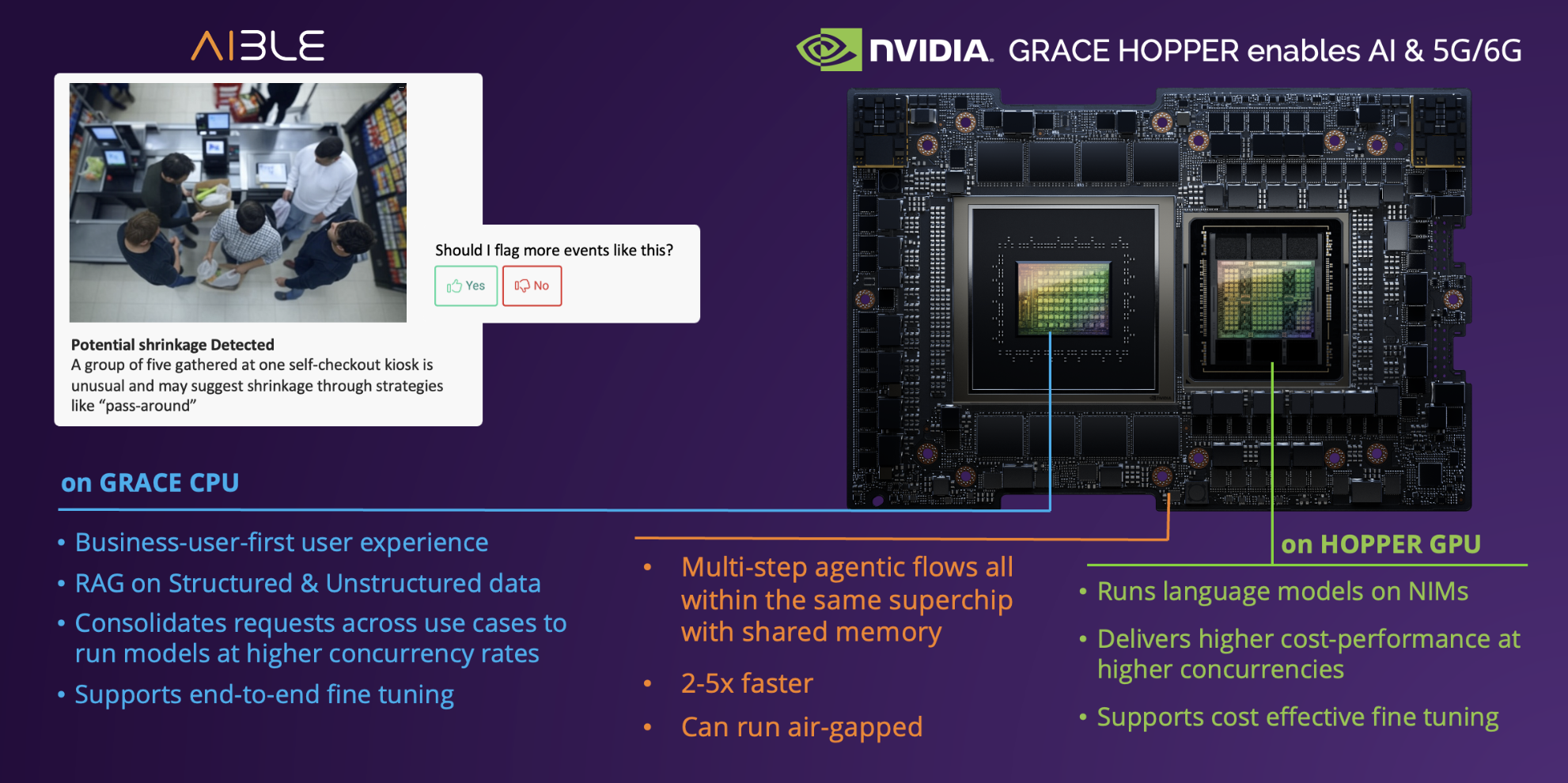
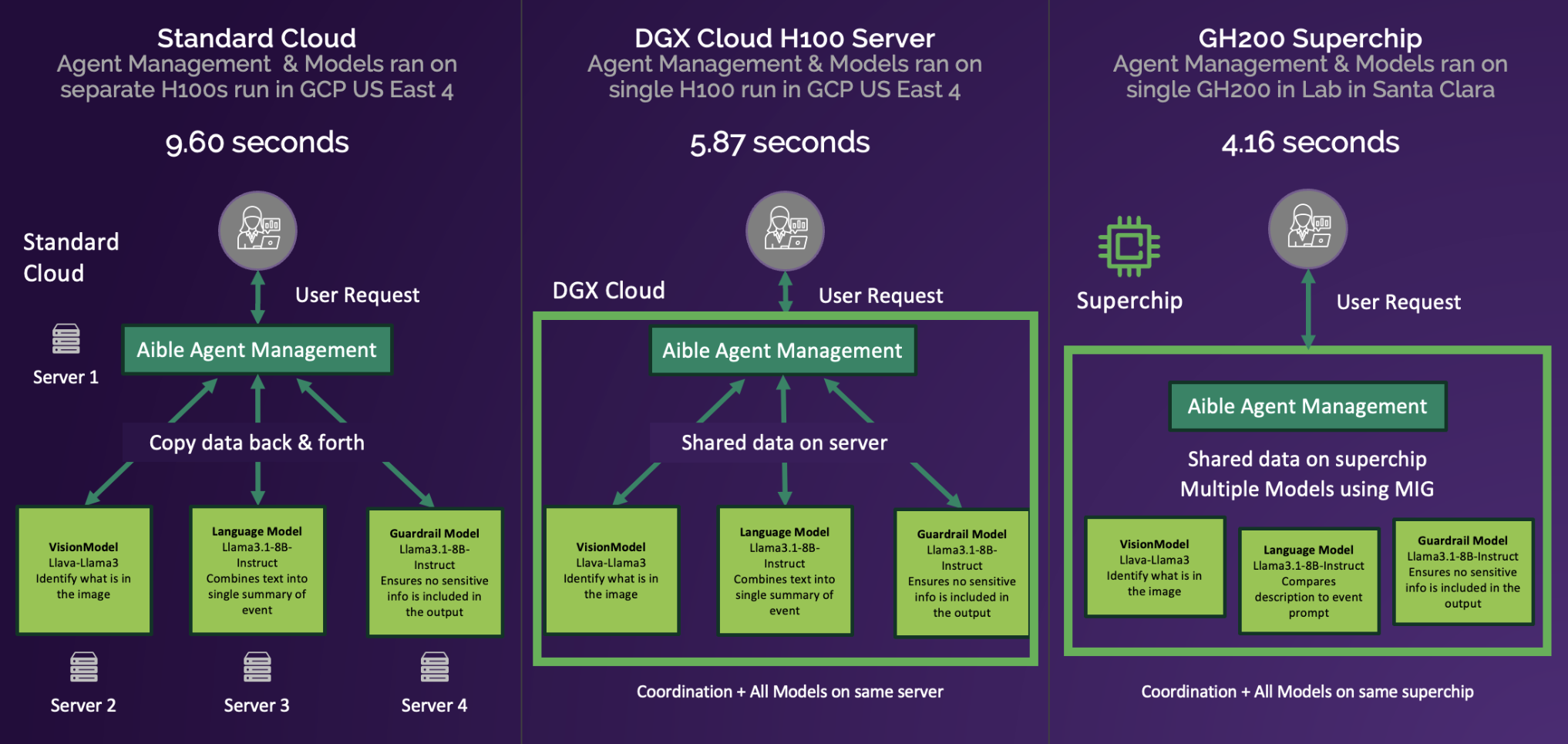

ACCESS NEWSWIRE
AI for Business Users at Enterprise Scale
Aible in collaboration with NVIDIA will feature how the joint solution empowers Fortune 500 companies and government organizations.

NVIDIA AI PODCAST
CVS Health and Aible
Delivering Enterprise AI with Rapid Prototyping

BLOG
NVIDIA DGX Cloud Serverless Inference
NVIDIA DGX Cloud Serverless Inference is an auto-scaling AI inference solution


