




NVIDIA Nemotron 3 Super Powers Aible SafeClaw
Long-Running Enterprise AI Agents
The popular open-source project OpenClaw is extremely powerful, but it solves tasks by generating arbitrary code on the fly. That approach does not work in enterprise IT departments because there would be no way to ensure that the model-generated code was safe, consistent, and compliant with IT governance requirements. Specifically in the world of enterprise analytics, code generated on the fly can lead to inconsistent results - two executives getting different answers on the exact same question - which is never acceptable from a trust perspective. Aible SafeClaw takes a different approach where users can test the plan generated by the long-running agent at setup time, approve which tools and models it can use and when, approve exactly which data sources it can access and how, and then approve that plan for ongoing operations. We do this by configuring a NVIDIA Nemotron 3 Super model which is well-suited for taking such constrained reasoning decisions. We are also working with the NVIDIA Nemotron team to further enhance this model to our unique needs through post-training.
Each tool that Aible SafeClaw leverages is completely deterministic and logged in the customer environment as Python code. Any dataset it accesses is only available as read-only datasets. Any calculations made on the data are mapped back to pre-approved templates for data transformations as opposed to code generated on the fly. Essentially, Aible SafeClaw forces agents to use the same golden data and golden transform, consistent with reuse principles that are well established in enterprise IT. We use NVIDIA NeMo Agent Toolkit to connect to a wide variety of tools and MCP servers securely and leverage Cisco’s AI Defense to further secure the models and tools.
Aible SafeClaw is easily extensible so organizations can plug in different kinds of long-running agents and agentic platforms. For example, for deep agents, especially deep research which may take minutes or even hours, we leverage NVIDIA A-IQ. When organizations want to use self-evolving agents or coding agents securely, we are leveraging an early access version of NVIDIA OpenShell to run such code in sandboxed environments with appropriate observability.
OpenClaw has validated the interest in running such agents ‘air-gapped’ in desktop devices, completely segregated from the Internet. Aible always believed customers would be more comfortable with building and testing agents in air-gapped environments and only then push them to enterprise environments. Another benefit of prototyping on the air-gapped devices is that the Nemotron 3 Super language model runs on the device itself. Thus, there are no unanticipated costs from agents spending unexpected amounts of tokens interacting back and forth.
Sha Edathumparampil, Chief Digital & Information Officer, Baptist Health South Florida wrote, "We have extensive experience running Aible agents in production and have seen firsthand how they can safely drive measurable operational impact at scale. For example, our proactive patient rescheduling agent has expanded from a single department to seven clinical service lines in just over a year, meaningfully improving patient access to timely care. We are also piloting Aible SafeClaw long-running agents using NVIDIA Nemotron 3 Super on DGX Spark at the edge and Nebius cloud at the core. Enterprise long-running agents can unlock significant value — particularly across silo’d core systems — but require the kind of IT governance and model monitoring enabled by Aible SafeClaw and NVIDIA NeMo Guardrails."
The Nemotron 3 Super model was crucial for unlocking the SafeClaw solution.
At GTC 2025, Aible demonstrated that a smaller, 8 billion parameter model, with just $5 of post-training, could outperform much larger models on specific enterprise tasks like asking questions on structured data with enterprise-specific terminologies. This typically happens because the generalized large language models have never seen the unique terminologies used at the specific enterprise, while the post-trained small model has been trained to specifically understand their unique data. For SafeClaw, we needed models that were optimized to perform the kind of planning and tool-calling required for enterprise long-running agent use cases, potentially even configured to the unique data of the enterprise. These models also needed to run on edge devices like the NVIDIA DGX Spark for secure, rapid prototyping. As Aible started to scale post-training via a fully automated end-to-end pipeline (more on that later), we ran into some very specific customer concerns that were addressed by the Nemotron 3 open models:
-
Legal concerns: In our experience, we have observed that enterprises are concerned about data governance and want to inspect the training data for these language models to avoid legal risk and potential lawsuits. Open source models are typically just ‘open weight’ meaning the final model is public, but all of the training data and the entire pipeline of how the model was created is not public. The Nemotron 3 models however are not just open weight, NVIDIA made the training data and the entire end-to-end pipeline public as well. This openness addresses questions related to training data and gives enterprises the confidence to deploy in production.
-
Organizational concerns: Enterprise customers are also concerned about long-term commitments to keeping these models open source and the parent organizations’ financial commitment to the cause. Given NVIDIA’s long commitment to open source and obvious enterprise resources, such concerns are far lower for an open source model like Nemotron.
-
Device optimization: Enterprises understand that open-source models require an entire ecosystem of support to run optimally. With the Nemotron models, NVIDIA has really thought through the end-to-end optimization. For example, the Nemotron model is optimized to run efficiently on each major NVIDIA processor. This was especially important in cases like the NVIDIA DGX Spark / Dell Pro Max with GB10 desktop supercomputers, where the device and the model are optimized for NVFP4 quantization to deliver optimal performance.
Given these customer concerns regarding open source models, Nemotron 3 from NVIDIA was the obvious choice for Aible SafeClaw and our next generation of Aible Intern models which are post-trained reasoning models based on major open source models.
The toughest part of post-training is often collecting the training data itself. Post-training typically requires examples of good and bad responses that the model can learn from. Aible bootstraps this by letting users provide feedback on the reasoning steps of the model to indicate where the model got things wrong, live updating the response based on that feedback, then confirming from the user that the updated response was correct. Aible can then use the combination of the original incorrect response and the later correct one to post-train the model. In traditional feedback, the user just provides a thumbs up / down. But there can be many reasons why the user may give a thumbs down. So, this is very low resolution feedback, like telling a pet “good dog / bad dog.” Whereas, the Aible approach empowers users to give more fine-grained feedback like “this is the correct calculation for gross margin for our company,” which enables users to train the AI like they would train an intern. We call this “train AI agents like interns not pets™” and thus our models are called Aible Interns.
Users Provide Focused Feedback on Reasoning Steps
Result is Adjusted Live and Responses are Saved for Post-Training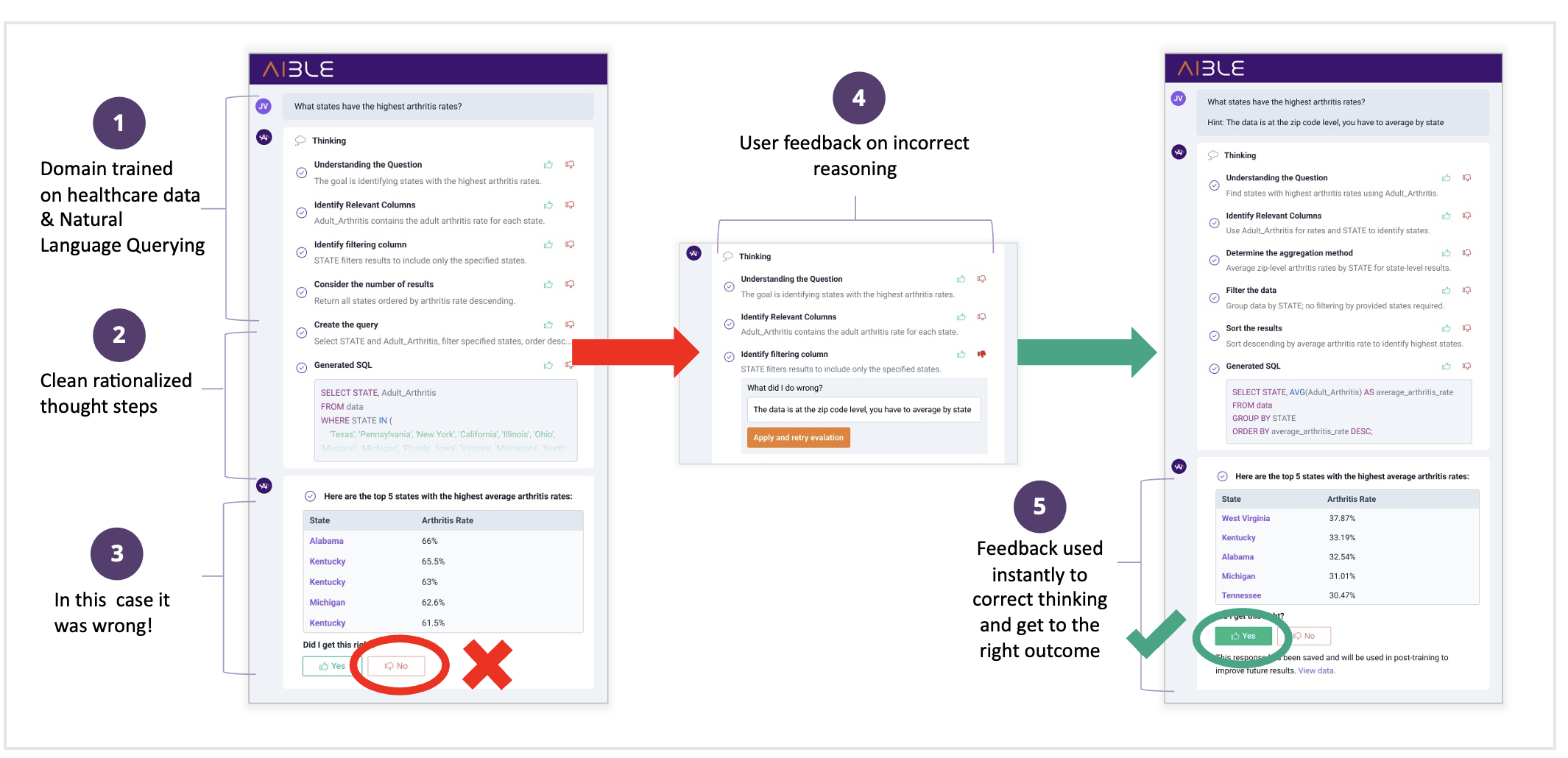
Given Aible’s post-training approach and focus on enterprise AI agents, three additional factors made the Nemotron 3 Super model a great choice.
-
Applicability for long-running agents: The next generation of Aible agents are long-running agents that leverage fleets of other agents and a wide variety of tools. In our experience with such long-running agents, reasoning models with Mixture of Experts (MoE) architectures tend to do much better with the ‘tool-calling’ and planning tasks that are critical for such agents. Of course Nemotron 3 is a family of reasoning models with MoE architecture. The Nemotron 3 Super specifically does a very good job on such tasks in our testing.
-
Ease of post-training: Post-training is a crucial tool that helps make agents specific to enterprise environments. But smaller models like Nemotron 3 Nano may not perform that well out of the box with complex enterprise data until it has been post-trained. This creates a chicken-and-egg problem for us where we know we can post-train a smaller model to perform the enterprise tasks, but can’t get it to work well enough out of the box to get the intern training process started. Here having the entire family of Nemotron 3 models is very useful. We can start the bootstrap process with the larger Nemotron 3 Super model or eventually the Ultra model. User feedback on such larger models can be used to post-train the smaller model. The smallest model that gets the job done with high enough accuracy can be deployed to be the final production model. This end-to-end post-training pipeline is powered by the NVIDIA NeMo Customizer, NVIDIA NeMo Evaluator, and the NVIDIA NeMo Data Designer solutions that we built right into Aible. Note that such a bootstrap approach cannot be started from a proprietary LLM because of the licensing restrictions of such models. You would need to start with an open-source model like Nemotron 3 Super or Nemotron 3 Nano that permits post-training using the output of that model.
-
Support for the DGX Spark & DGX Station: Our customers want to quickly prototype agents in air-gapped environments where they have no surprise per-token bills. For example, Shay Wilson, CIO at State of Alaska Legislative Affairs Agency wrote, “We built our first Aible AI agent running on NVIDIA DGX Spark in 5 minutes. Running on our DGX Spark in a secure air-gapped environment allows me to prototype confidently, eliminate surprise spending, and scale to broader use cases only when we’re ready.” As a result, we are early supporters of the DGX Spark and the new DGX Station desktop supercomputers from NVIDIA. The Nemotron 3 Nano and Super models run extremely efficiently on the DGX Spark. But we could not fit the Super on the Spark until it was quantized to the right specifications for the DGX Spark. This is where NVIDIA’s end-to-end engineering work came to the rescue - they had already planned for these models and devices to work optimally together and helped us get the right model for the DGX Spark.
Next Steps
We thank the NVIDIA NeMo and NVIDIA Nemotron teams for close collaboration and we look forward to optimally post-train Nemotron 3 MoE models. Based on our testing we believe focusing post-training efforts on specific ‘Experts’ would lead to better results than trying to post-train the entire MoE model. We look forward to further improving the Nemotron 3 models via expert-specific post-training as NVIDIA releases such capabilities in the NVIDIA NeMo Customizer.


