There are three fatal flaws of the world’s current approach to AI. Today Aible announced the personal AI on the personal supercomputer that solves these flaws.

All of Aible’s enterprise AI Agent capabilities that have been proven on all major clouds and HPE Private Cloud for AI (PCAI), can now run on a single small desktop server in the form of the NVIDIA DGX Spark. Aible can run the agents superfast by running the user experience, the agent coordination, agent tools including vector databases, and the language models, all on the same silicon with shared memory and communicate synchronously between them without writing anything to disk. This is faster end-to-end than current alternatives because agents on the cloud have to communicate asynchronously, writing data back and forth between different servers running the models and tools, and coordination logic. It can do all this completely air-gapped to ensure complete privacy. And it does so at a fixed annual cost per user so there are no surprise language model expenses. The device and all software is included in the annual cost.
1. The market is obsessing over complex generalized agents that are expensive to build and govern, instead of agents that improve individual business users’ lives:
Aible works with several Fortune 500s and the common pattern is that the scope of an agent is constantly expanded until it is no longer good at any one thing. At the same time, users constantly come up with ideas that can save them one hour a day. Over and over again, we have seen them build such an agent that is ‘good enough’ for what they want in a matter of minutes. For an employee with a fully loaded annual cost of $100,000, a single such agent that saves them 1 hour a day delivers a $10,000 impact. But $10,000 seems too small a payback to pursue building an agent? Could we maybe generalize this agent so 1,000 people can use it? So that we can have a $10 Million impact? But now the agent has to be good enough to meet the superset of the needs of the 1,000 users, it has to be governed appropriately, the operating costs have to be managed, etc. and the cost of creating and managing the agent just grew by more than 1000X. So, your ROI as a percent of costs actually dropped.
Now, individual business users can build agents that improve their own lives because:
-
They can make the agent uniquely their own for their own ‘job to be done’ – because it is their own personal agent running on their own personal supercomputer
-
There is no security risk from the agent – because it runs solely on their own personal supercomputer
-
There is no marginal cost from the agent – because it runs solely on their own personal supercomputer
But can users really build their own agents? Well, we have already proven that they can. For example, at the State of Nebraska hackathon, 36 users with no prior training, and most with no AI expertise, built 222 agents in 90 minutes. Users can also share their agents or agent templates with other users or publish them to internal or public marketplaces. Also with a push of a button, the agents can be published at enterprise scale on all three major clouds or in private cloud solutions from HPE & Dell.
2. The market is trying to convince us that it is worth sacrificing our privacy to Large Language Models?
Clearly, we want the benefits of powerful AI AND our individuality and privacy. Enterprises simply cannot give their data to a public AI. Moreover, agents are now beginning to save their interactions with us as ‘memory’ that they can use later to inform future interactions. This significantly increases the privacy risk from such systems. And thus, unless we collectively decide to ignore privacy risk, Large Language Model efforts will essentially remain consumer solutions, because they can only learn from data in the public domain (or at least accessible from public sources). We have already proven that small models that are post-trained for specific tasks, data, terminologies, processes perform much better than 100 times larger generalized models. Then why are we not building thousands and millions of specialized agents that do specific tasks much better than generic Large Language Models, and in the aggregate can already deliver significant business value today?
Now there is no compromise between accuracy and privacy because:
-
There is no privacy risk from the agent – because the user’s data and the ‘memory’ of their chat interactions remain solely on the personal supercomputer
-
Accuracy is improved – because multiple specialized post-trained variants of the models (different LORA layers but the same base model) can run efficiently on the same personal supercomputer
-
Complexity is reduced and thus the overall solution is more efficient – because a given user uses a small subset of use cases, agentic tools, and model variants, these can be kept efficiently in the 128 GB of built-in fast memory and thus run more optimally
But can users really post-train models themselves? Can these post-trained models actually outperform larger models? We have already proven they can. Business users can easily provide focused feedback on the reasoning steps of the models. Aible completely automates the post-training process from data collection to post training to validation to model management. We even showed that a small model like an 8 Billion parameter Llama variant can outperform 100 times larger proprietary models with 22 minutes of post-training. Note that we are already running 120 Billion parameter models on the NVIDIA DGX Spark and believe it will efficiently hold 405 Billion parameter models as well. So, the open source ‘small’ models here are much closer in size to the proprietary large language models that are only 2 to 10 times larger at this point.
3. The market is rewarding platform-specific AI even though we know the greatest power of AI will come from spanning silos:
An order to cash AI that can look at an order, check against contract terms, check inventory availability, estimate payment risk, optimize delivery options, then auto-generates the order response is far more powerful than agents doing each individual step. An agent that runs at the telco edge to detect issues, checks with a centralized agent to see if similar patterns have been encountered elsewhere, analyzes prior repair logs in a third system to formulate a response and automatically applies a fix via a fourth system is far more powerful than an agent built into the service ticket system alone. Enterprises always span platforms, different clouds / on prem / edge, different CRM / ERP / Finance, different geographies, etc. then why are we building point solutions when the value will come from AI systems that will span them all?
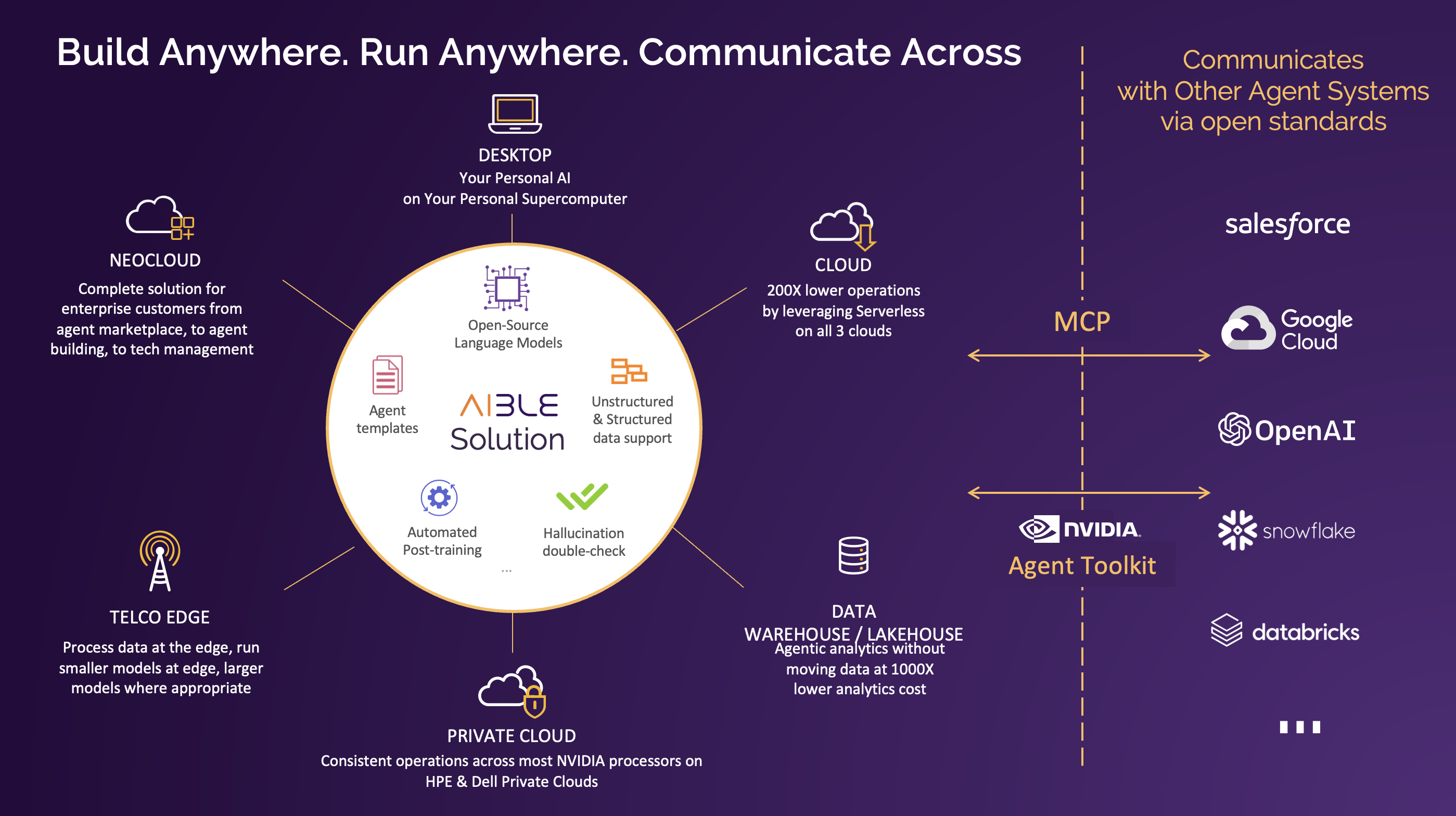
Agents can now run on any platform while coordinating agents across multiple platforms because:
-
The exact same code that is running on the NVIDIA DGX Spark also runs on all three major clouds, on HPE and Dell Private Clouds, on most NVIDIA processors, and at the telco edge as proven in the NVIDIA Aerial Lab and by Fujitsu/1Finity. Lighter workloads can even run on Intel Xeon processors.
-
The Aible agents can process data where it is in Snowflake, Big Query, Databricks, Redshift, etc. and only move necessary metadata to the personal supercomputer where the agents are running
-
Aible uses open standards like Model Context Protocol (MCP) and open source capabilities like the NVIDIA Agent Toolkit that enables it to talk to a wide variety of agents that are being built into various platforms. Aible agents can talk to and coordinate across both Aible agents and standards compliant external agents.
But can a startup really run across all these platforms? Our partners have already publicly validated that we can. See NVIDIA, Intel, HPE, Google, Snowflake, AWS, Microsoft, etc. and several other announcements are imminent. In fact, we spent seven years building the comprehensive solution that could be truly platform and model agnostic. The integration with other types of agents are assured by the open standards and tooling that we have adopted.
Aible on DGX Spark was launched at the Gartner Symposium
There is no better proof than the reactions of real users. At the Gartner Symposium event in October 2025, we asked users to build their own agents using Aible on the NVIDIA DGX Spark. Here are some videos of those interactions. The excitement is palpable.

Aible on DGX Spark completes our vision where you can build agents anywhere and deploy everywhere. We believe business users will use the DGX Spark to build many different agents securely in their own private supercomputer, test which ones have the most business impact, and then scale some of these agents to many users via cloud or private cloud deployments.
Now where do we go from here? The DGX 1 was released 9 years before the DGX Spark. The DGX Spark is 1000X more powerful and 8X smaller. In the last couple of years, open source models have gone from 7 Billion parameters to over 405 Billion parameters. The personal supercomputer will only get smaller and the personal AI will only get smarter.
Enterprise users will start using this solution today. However, as the cost and size gets lower still, it will be a truly personal device that each of us will personally own - just like a phone, or perhaps as part of it. In the not so distant future, each of us will have our own personal AI on our own personal supercomputers that keep our data private, understand our needs across use cases perfectly, and efficiently interact with the necessary external systems to get the job done. That is the empowering future Aible is building. Thus, our enduring motto since 2018: I am Aible!